Standards-based, Open-source Middleware for Predictive Analytics Applications
Convert your fitted Scikit-Learn, R or Apache Spark models and pipelines into the standardized Predictive Model Markup Language (PMML) representation, and make quick and dependable predictions in your Java/JVM application.
Standardization enables automation, which in turn enables higher efficiency and higher quality business processes.

Why choose JPMML software?
 The gold standard
The gold standard
PMML embodies decades' worth of knowledge and best practices in the Tabular ML field. Do not dismiss it, build on it!
- Joint effort. PMML is developed and maintained by the Data Mining Group (DMG), which is an independent consortium between major statistics and data mining software vendors.
- Backwards- and forwards-compatible. PMML version changes are incremental/evolutionary. Any PMML model that has been generated since early 2000s can be put into production today.
- No challengers. PMML outsmarts and outdoes alternative Tabular ML standardization efforts, whether commercial or (F)OSS.
 The “less code, less coding” approach
The “less code, less coding” approach
PMML is designed around human-oriented data structures (as opposed to computer-executable code). By eliminating the code component, PMML eliminates the need for coding roles and coding activities within the organization. The data science team and the application development team can focus on their core competencies; there is no need for extra hybrid teams (“MLOps” or “DevOps”), extra inter-team communication.
- Functionally complete. PMML captures all of feature engineering, modelling and decision engineering.
- Reductionist. PMML promotes a one — the best — way of conceptualizing things. For example, all linear models collapse into a singular PMML “regression table” data structure, all decision tree models collapse into a singular PMML “tree” data structure, etc. Less to learn and remember.
- Auditable and verifiable. PMML holds ample metadata for quality assurance and quality control purposes. A PMML model is a fully self-contained and self-informed artifact, which takes active part in ensuring that its predictions are reliable and correct.
- Explainable. PMML operates at high, real-world abstraction level. The inner workings of a PMML model are easily approachable even for non-experts.
- Stable and secure. PMML models do not require any maintenance while in storage. PMML models cannot be attacked or breached while in production.
 Full software stack
Full software stack
The Java PMML API software project provides a right Java-based tool for every PMML job. End user-facing components are equipped with command-line and/or REST interface, which enables integration with alternative application platforms.
- Layered library architecture. Specialized, high-level APIs are derived from common low-level APIs. Simple and minimalistic dependency graph. Automatic assembly of 5 to 10 MB application-oriented library sets.
- Pure Java. The same library set works on any Java SE 8/11 compatible Java VM.
- Most efficient conversion. JPMML converters support most common Tabular ML frameworks, model and transformation types. They perform deep examinations and analyses on the incoming pipeline object in order to come up with the best encoding plan. Sub-optimal encodings (by lesser PMML converters) are difficult to correct after the fact, and will degrade the deployment experience significantly.
- Most efficient evaluation. JPMML evaluators are among the smallest and fastest general-purpose scoring engines for the Java/JVM platform. They challenge the performance of any Tabular ML framework (with or without hardware acceleration) in real-time scoring scenarios.
- End-to-end reproducibility guarantee. JPMML predictions always match the original Tabular ML framework predictions, as proven by extensive integration tests.
 Vendor backing and support
Vendor backing and support
In the long run, you get what you paid for. The choice is between upfront, fixed monetary costs vs. after-the-fact, indeterminate business costs.
- Commitment. Openscoring is the only pure-PMML company in existence today.
- Longevity and reliability. Openscoring has over eight years of public track record. Openscoring will be there for the entirety of your software project, your business venture.
- Proof of work. Openscoring conducts original research, and is known for delivering many “Firsts” and “Bests” in the field.
- Direct, personal connection.
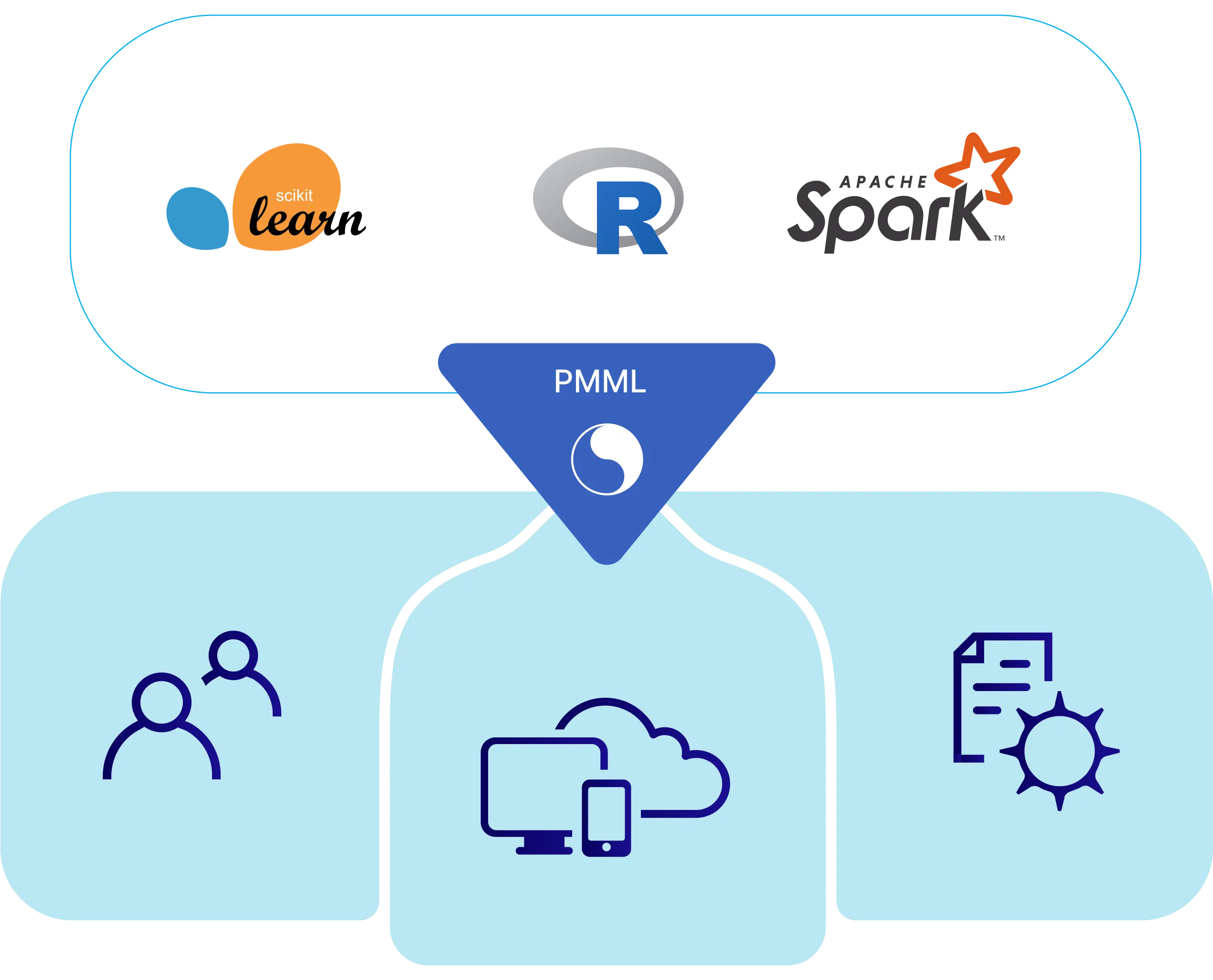
Products
JPMML software is grouped into three product verticals:
Model conversion involves translating a fitted model or pipeline object from the original Tabular ML representation into the PMML representation, and saving it as a PMML document.
Scikit-Learn
Install and import the SkLearn2PMML package.
Replace usages of the sklearn.pipeline.Pipeline class with the sklearn2pmml.pipeline.PMMLPipeline class.
Fit as usual. Export the fitted PMMLPipeline object into a PMML XML file using the sklearn2pmml.sklearn2pmml(obj, path) utility function:
from sklearn2pmml import sklearn2pmml
from sklearn2pmml.pipeline import PMMLPipeline
pipeline = PMMLPipeline([...])
pipeline.fit(X, y)
# Enable automated QA
pipeline.verify(X.sample(100))
sklearn2pmml(pipeline, "MyPipeline.pmml.xml")R
Install and import the R2PMML package.
Fit as usual. Export the fitted model object into a PMML XML file using the r2pmml::r2pmml(obj, path) utility function:
library("r2pmml")
glm.obj = glm(y ~ ., data = df)
# Enable automated QA
glm.obj = r2pmml::verify(glm.obj, newdata = sample_n(df, 100))
r2pmml::r2pmml(glm.obj, "MyPipeline.pmml.xml")Apache Spark
Install and import the JPMML-SparkML library.
Fit as usual. Construct an org.jpmml.sparkml.PMMLBuilder object based on the DataFrame schema and the fitted PipelineModel object, customize it, and export into a PMML XML file using the PMMLBuilder#buildFile(File) builder method:
import org.jpmml.sparkml.PMMLBuilder
val pipeline = new Pipeline().setStages(...)
val pipelineModel = pipeline.fit(df)
var pmmlBuilder = new PMMLBuilder(df.schema, pipelineModel)
// Enable automated QA
pmmlBuilder = pmmlBuilder.verify(df.sample(false, 0.01).limit(100))
pmmlBuilder.buildFile(new File("MyPipeline.pmml.xml"))Data science packages:
Data application engineering libraries:
PMML engineering libraries:
Model scoring involves loading a PMML object from a PMML document, and making predictions for new data records. The scoring component resides in the application space, right between “data source” and “data sink” components, which makes the workflow most suitable for real-time prediction (sub-microsecond turnaround times).
Java
Install and import the JPMML-Evaluator library.
Build an org.jpmml.evaluator.Evaluator object based on a PMML XML file.
Verify the state of the evaluator using the previously embedded dataset of tricky data records:
import org.jpmml.evaluator.Evaluator;
import org.jpmml.evaluator.LoadingModelEvaluatorBuilder;
Evaluator evaluator = new LoadingModelEvaluatorBuilder()
.load(new File("MyPipeline.pmml.xml"))
.build();
// Perform automated QA
evaluator.verify();Score new data records. The ordering of dictionary entries is not significant, because in PMML fields are identified by name, not by position:
Map<String, Object> arguments = new HashMap<String, Object>();
arguments.put("temperature", 75);
arguments.put("humidity", 55.0);
arguments.put("windy", false);
arguments.put("outlook", "overcast");
Map<String, ?> results = evaluator.evaluate(arguments);
String whatIdo = (String)results.get("whatIdo");Python
Install and import the JPMML-Evaluator-Python package. Establish Python-to-Java connectivity by launching a JPype, PyJNIus or Py4J backend. Load, verify and score. The Python API is designed after the Java API.
from jpmml_evaluator import make_evaluator
evaluator = make_evaluator("MyPipeline.pmml.xml")
# Perform automated QA
evaluator.verify()
arguments = {
"temperature" : 75,
"humidity": 55.0,
"windy" : False,
"outlook" : "overcast"
}
results = evaluator.evaluate(arguments)
whatIdo = results["whatIdo"]Data science packages:
Data application engineering libraries:
PMML engineering libraries:
Turn any PMML document into a RESTful web service, and interact with it from any application, anywhere! The workflow is subject to network latency, and is therefore more suitable for less time-sensitive tasks such as web form prediction and batch prediction (tens to hundreds of milliseconds turnaround times).
Server-side
Download and run the Openscoring server executable JAR file:
$ java -jar openscoring-server-executable-${version}.jarClient-side
Performing a full deploy-score-undeploy workflow using a command-line cURL application:
$ curl -X PUT --data-binary MyPipeline.pmml.xml -H "Content-type: text/xml" http://localhost:8080/openscoring/model/MyPipeline
$ curl -X POST --data-binary @MyNewData.csv -H "Content-type: text/plain; charset=UTF-8" http://localhost:8080/openscoring/model/MyPipeline/csv > MyNewData-results.csv
$ curl -X DELETE http://localhost:8080/openscoring/model/MyPipelineDoing the same using the Openscoring-Python package:
from openscoring import Openscoring
os = Openscoring(base_url = "http://localhost:8080/openscoring")
os.deployFile("MyPipeline", "MyPipeline.pmml.xml")
os.evaluateCsvFile("MyPipeline", "MyNewData.csv", "MyNewData-results.csv")
os.undeploy("MyPipeline")Doing the same using the Openscoring-R package:
library("openscoring")
os = new("Openscoring", base_url = "http://localhost:8080/openscoring")
deployFile(os, "MyPipeline", "MyPipeline.pmml.xml")
evaluateCsvFile(os, "MyPipeline", "MyNewData.csv", "MyNewData-results.csv")
undeploy(os, "MyPipeline")What are JPMML software license terms?
The base layer of JPMML software is released under the BSD 3-Clause License.
However, the higher and more sophisticated layers of JPMML software are released under the GNU Affero General Public License, version 3.0 (AGPL-v3).
When in doubt, see the contents of the LICENSE.txt file at the root of each product's GitHub repository.
Your rights and obligations under different licenses are summarized in the adjacent table.
If the terms and conditions of AGPL-v3 are not acceptable, then it is possible to enter into a licensing agreement with Openscoring, which re-licenses the desired parts of the JPMML software from AGPL-v3 to BSD 3-Clause License. The re-licensing process is simple and straightforward. Please initiate it by clicking the button below:
Request for BSD 3-Clause License| AGPL-v3 | BSD 3-Clause License | ||
| Type: |
Protective (copyleft)
|
Permissive (copyright)
|
|
| Can use commercially: |
Yes
|
Yes
|
|
| Can modify and distribute: |
Yes
|
Yes
|
|
| Must disclose source form to end users: |
Yes
|
No
|
|
| Can sublicense: |
No
|
Yes
|

Further assistance and discussion
Openscoring sells software, but provides support services for free.
Technical questions, feature requests, bug reports, etc. about specific products?
Please open a new GitHub issue with one of the Java PMML API or Openscoring REST API software projects.
General questions about (J)PMML?
Please open a new thread in the JPMML Mailing List.
Other exciting opportunities?
Please contact privately.

